STL里sort算法用的是什么排序算法?
实现逻辑
STL的sort算法,数据量大时采用QuickSort快排算法,分段归并排序。一旦分段后的数据量小于某个门槛,为避免QuickSort快排的递归调用带来过大的额外负荷,就改用Insertion Sort插入排序。如果递归层次过深,还会改用HeapSort堆排序。
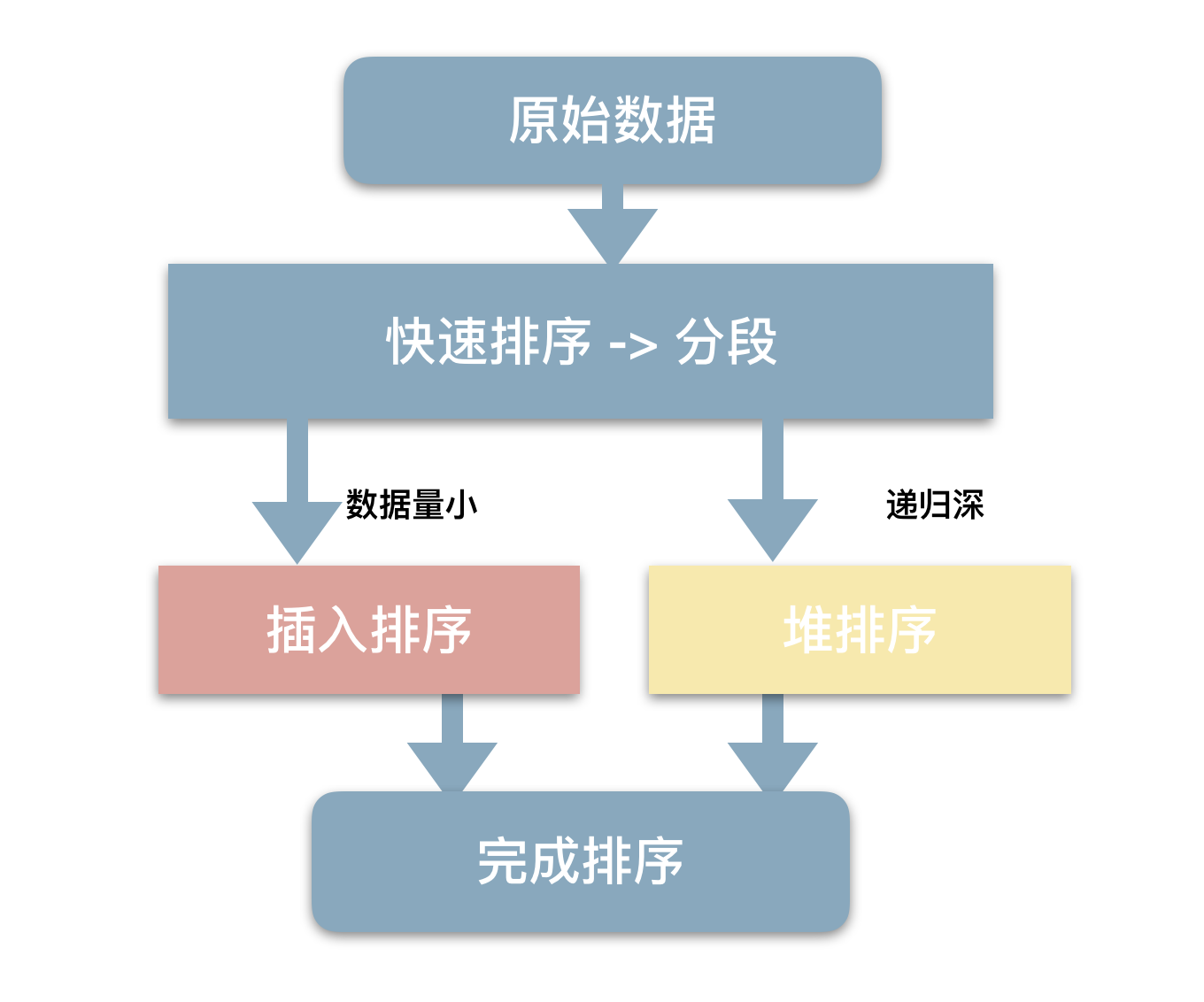
结合快速排序-插入排序-堆排序 三种排序算法。
for(auto a:b)
for(auto a:b)中b为一个容器,效果是利用a遍历并获得b容器中的每一个值,但是a无法影响到b容器中的元素。
vector arr;
arr.push_back(1);
arr.push_back(2);
for (auto n : arr)
{
cout << n << endl;
}
for(auto &a:b)中加了引用符号,可以对容器中的内容进行赋值,即可通过对a赋值来做到容器b的内容填充。
map与unordered_map
需要引入的头文件不同
map: #include < map >
unordered_map: #include < unordered_map >
内部实现机理不同
map: map内部实现了一个红黑树(红黑树是非严格平衡二叉搜索树,而AVL是严格平衡二叉搜索树),红黑树具有自动排序的功能,因此map内部的所有元素都是有序的,红黑树的每一个节点都代表着map的一个元素。因此,对于map进行的查找,删除,添加等一系列的操作都相当于是对红黑树进行的操作。map中的元素是按照二叉搜索树(又名二叉查找树、二叉排序树,特点就是左子树上所有节点的键值都小于根节点的键值,右子树所有节点的键值都大于根节点的键值)存储的,使用中序遍历可将键值按照从小到大遍历出来。
unordered_map: unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。哈希表详细介绍
优缺点以及适用处
map:
优点:
有序性,这是map结构最大的优点,其元素的有序性在很多应用中都会简化很多的操作
红黑树,内部实现一个红黑书使得map的很多操作在lgn的时间复杂度下就可以实现,因此效率非常的高
缺点: 空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率,但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间
适用处:对于那些有顺序要求的问题,用map会更高效一些
unordered_map:
优点: 因为内部实现了哈希表,因此其查找速度非常的快
缺点: 哈希表的建立比较耗费时间
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
总结:
内存占有率的问题就转化成红黑树 VS hash表 , 还是unorder_map占用的内存要高。
但是unordered_map执行效率要比map高很多
对于unordered_map或unordered_set容器,其遍历顺序与创建该容器时输入的顺序不一定相同,因为遍历是按照哈希表从前往后依次遍历的
map和unordered_map的使用
unordered_map的用法和map是一样的,提供了 insert,size,count等操作,并且里面的元素也是以pair类型来存贮的。其底层实现是完全不同的,上方已经解释了,但是就外部使用来说却是一致的。
#include <iostream>
#include <unordered_map>
#include <map>
#include <string>
using namespace std;
int main()
{
//注意:C++11才开始支持括号初始化
unordered_map<int, string> myMap={{ 5, "张大" },{ 6, "李五" }};//使用{}赋值
myMap[2] = "李四"; //使用[ ]进行单个插入,若已存在键值2,则赋值修改,若无则插入。
myMap.insert(pair<int, string>(3, "陈二"));//使用insert和pair插入
//遍历输出+迭代器的使用
auto iter = myMap.begin();//auto自动识别为迭代器类型unordered_map<int,string>::iterator
while (iter!= myMap.end())
{
cout << iter->first << "," << iter->second << endl;
++iter;
}
//查找元素并输出+迭代器的使用
auto iterator = myMap.find(2);//find()返回一个指向2的迭代器
if (iterator != myMap.end())
cout << endl<< iterator->first << "," << iterator->second << endl;
system("pause");
return 0;
}
Stack和pair的基本用法
Stack(栈)是一种后进先出的数据结构
使用STL的STACK需要的头文件
#include <stack>
Stack的构造
stack< int > first ; // 构造一个存放int类型的空栈,size=0;
成员函数
push
mystack.push(i);
push函数将参数元素加入栈中,没有返回值(例如这里循环将0,1,2,3,4加入栈中,注意栈顶元素是4)
size
mystack.size()
size函数返回栈的大小(如果有5个元素,size=5)
empty
mystack.empty()
empty函数返回一个bool值,栈为空时返回true,否则返回false
top
mystack.top();
top函数的返回值是栈顶元素(注意并没有删掉栈顶元素
pop
mystack.pop();
pop函数将栈顶元素删掉,没有返回值
emplace
stack<Node> mystack;
mystack.emplace(1,2);
emplace函数可以将一个元素加入栈中,与push的区别在于:emplace可以直接传入Node的构造函数的参数,并将构造的元素加入栈中
mystack.push(1,2); //编译不通过,要达到上面的效果需要手动构造,例如mystack.push(Node(1,2));
Node p = mystack.top();
cout << p.a << " " << p.b << endl;
stack<Node> my2;
my2.swap(mystack); //swap函数可以交换两个栈的元素
pair
pair是将2个数据组合成一组数据, pair的实现是一个结构体,主要的两个成员变量是first second 因为是使用struct不是class,所以可以直接使用pair的成员变量。。
头文件
#include <utility>
类模板:
template<class T1,class T2> struct pair
参数:T1是第一个值的数据类型,T2是第二个值的数据类型。
功能:pair将一对值(T1和T2)组合成一个值,
pair<T1, T2> p1(v1, v2); //创建一个pair对象,它的两个元素分别是T1和T2类型,其中first成员初始化为v1,second成员初始化为v2。
make_pair(v1, v2); // 以v1和v2的值创建一个新的pair对象,其元素类型分别是v1和v2的类型。
p1 < p2; // 两个pair对象间的小于运算,其定义遵循字典次序:如 p1.first < p2.first 或者 !(p2.first < p1.first) && (p1.second < p2.second) 则返回true。
p1 == p2; // 如果两个对象的first和second依次相等,则这两个对象相等;该运算使用元素的==操作符。
p1.first; // 返回对象p1中名为first的公有数据成员
p1.second; // 返回对象p1中名为second的公有数据成员
创建pair
在创建pair对象时,必须提供两个类型名,两个对应的类型名的类型不必相同
pair<string, string> anon; // 创建一个空对象anon,两个元素类型都是string
pair<string, int> word_count; // 创建一个空对象 word_count, 两个元素类型分别是string和int类型
pair<string, vector<int> > line; // 创建一个空对象line,两个元素类型分别是string和vector类型
卡特兰数的应用
题目:12个高矮不同的人,排成两排,每排必须是从矮到高排列,而且第二排比对应的第一排的人高,问排列方式有多少种?
从题目可知,要把12个人分成两排,而且每个人的身高都不一样,所以不管怎么分组,他们的身高都可以按从小到大排列,只是要求第二排比对应第一排的人高。
思路是:把这个问题化成出栈次序(典型的卡特兰数的应用)求解。
因为每排有6个人,所以,设第一排的6个人分别为A,B,C,D,E,F(还不确定他们是12个人中的哪一个)
对这(A,B,C,D,E,F)执行入栈和出栈(从A到F),从他们出栈序列就可以找到这A,B,C,D,E,F是12个人中的具体哪一个。
方法是:
假设这12个人的身高分别为1,2,3,4,5,6,7,8,9,10,11,12
设入栈为“1”,出栈为“0”,这样一系列的入栈和出栈就可以由一串1和0构成。例如出栈序列为A,B,C,D,E,F,则对应的这一串1和0为:101010101010。利用这串1和0,就可以找到这12个人哪个是第一排的,哪个是第二排的。把这12个人的身高从小到大排列,1,2,3,4,5,6,7,8,9,10,11,12 利用刚刚得到的那串1和0,和他们的身高序列一一对上。则对应1的身高为1,3,5,7,9,11;对应0的身高为2,4,6,8,10,12。1对应的其实就是第一排的人,0对应的就是第二排的人。再看看出栈序列为A,C,D,B,F,E对应的1和0串为101101001100,则第一排的身高序列为1,3,4,6,9,10;第二排的身高序列为2,5,7,8,11,12。这样,每一种出栈序列就对应每一种排列方式,而且是一一对应的。因为出栈序列是典型的卡特兰数的应用(百度百科就有举例),这样就可以很直接的写出结果C(12,6)/(6+1)=132,则总共有132种排列方式。
下面解释为什么可以用那一串1和0就可以确定他们的排列方式
因为出栈总是相对于入栈的,要想出栈,则必定先有入栈。所以1总是先于0出现,也就是说可以先找到身高比较矮的插入第一排,把身高比之前插入第一排的还要高的插入第二排(每一个0对应的身高都比前面所有的1对应的身高还要高,而且0和1的数量又是相等的,第几个1对应第几个0),这样就可以全部找到第二排比对应的第一排的人高的全部排列方式。不同的出栈序列决定不同的排列方式。有多少种出栈序列就有多少种排列方式,这样就很明显看出来是卡特兰数的应用了。
经典问题
2.1 进出栈序列
这是一道 最经典 的入门级卡特兰数题目,如果能把这题看懂,相信后面的题目也能迎刃而解。
题目描述
n 个元素进栈序列为:1,2,3,4,…,n,则有多少种出栈序列。
思路
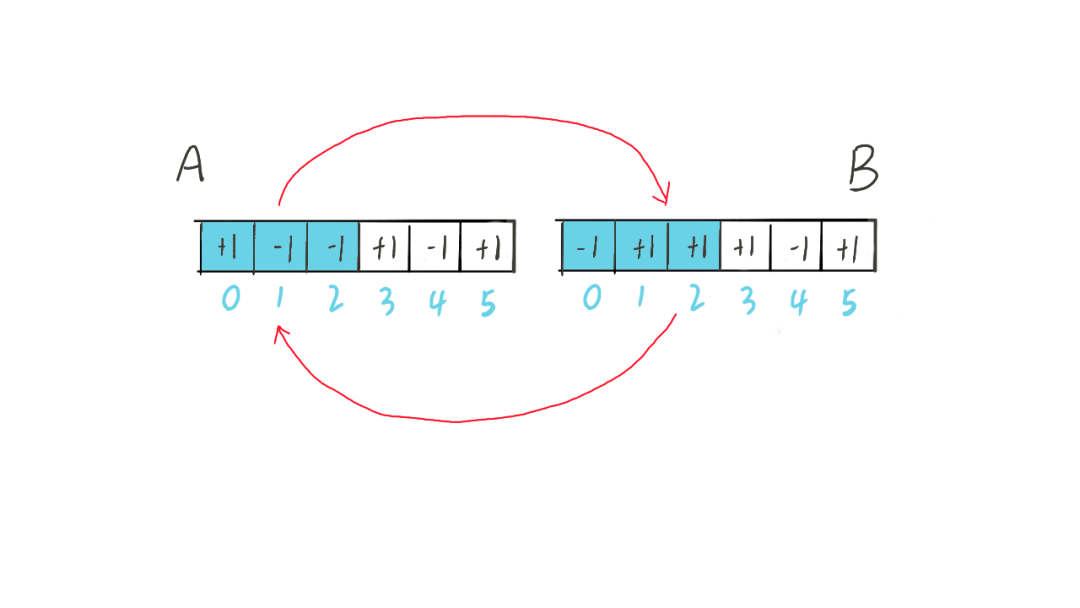
我们将进栈表示为 +1,出栈表示为 -1,则 1 3 2 的出栈序列可以表示为:+1 -1 +1 +1 -1 -1。
<img src=”https://pic2.zhimg.com/80/v2-fe28b25ed263230250d0a3c68344b0d5_1440w.jpg"style="zoom:50%;" />
根据栈本身的特点,每次出栈的时候,必定之前有元素入栈,即对于每个 -1 前面都有一个 +1 相对应。因此,出栈序列的 所有前缀和 必然大于等于 0,并且 +1 的数量 等于 -1 的数量。
接下来让我们观察一下 n = 3 的一种出栈序列:+1 -1 -1 +1 -1 +1。序列前三项和小于 0,显然这是个非法的序列。
如果将 第一个 前缀和小于 0 的前缀,即前三项元素都进行取反,就会得到:-1 +1 +1 +1 -1 +1。此时有 3 + 1 个 +1 以及 3 - 1 个 -1。
因为这个小于 0 的前缀和必然是 -1,且 -1 比 +1 多一个,取反后,-1 比 +1 少一个,则 +1 变为 n + 1 个,且 -1 变为 n - 1 个。进一步推广,对于 n 元素的每种非法出栈序列,都会对应一个含有 n + 1 个 +1 以及 n - 1个 -1 的序列。
如何证明这两种序列是一一对应的?
假设非法序列为 A,对应的序列为 B。每个 A 只有一个”第一个前缀和小于 0 的前缀“,所以每个 A 只能产生一个 B。而每个 B 想要还原到 A,就需要找到”第一个前缀和大于 0 的前缀“,显然 B 也只能产生一个 A。
每个 B 都有 n + 1 个 +1 以及 n - 1 个 -1,因此 B 的数量为 ,相当于在长度为 2n 的序列中找到
n + 1个位置存放 +1。相应的,非法序列的数量也就等于 。
出栈序列的总数量共有 ,因此,合法的出栈序列的数量为
。
此时我们就得到了卡特兰数的通项 ,至于具体如何计算结果将会在后面进行介绍。
2.2 括号序列
题目描述
n 对括号,则有多少种 “括号匹配” 的括号序列
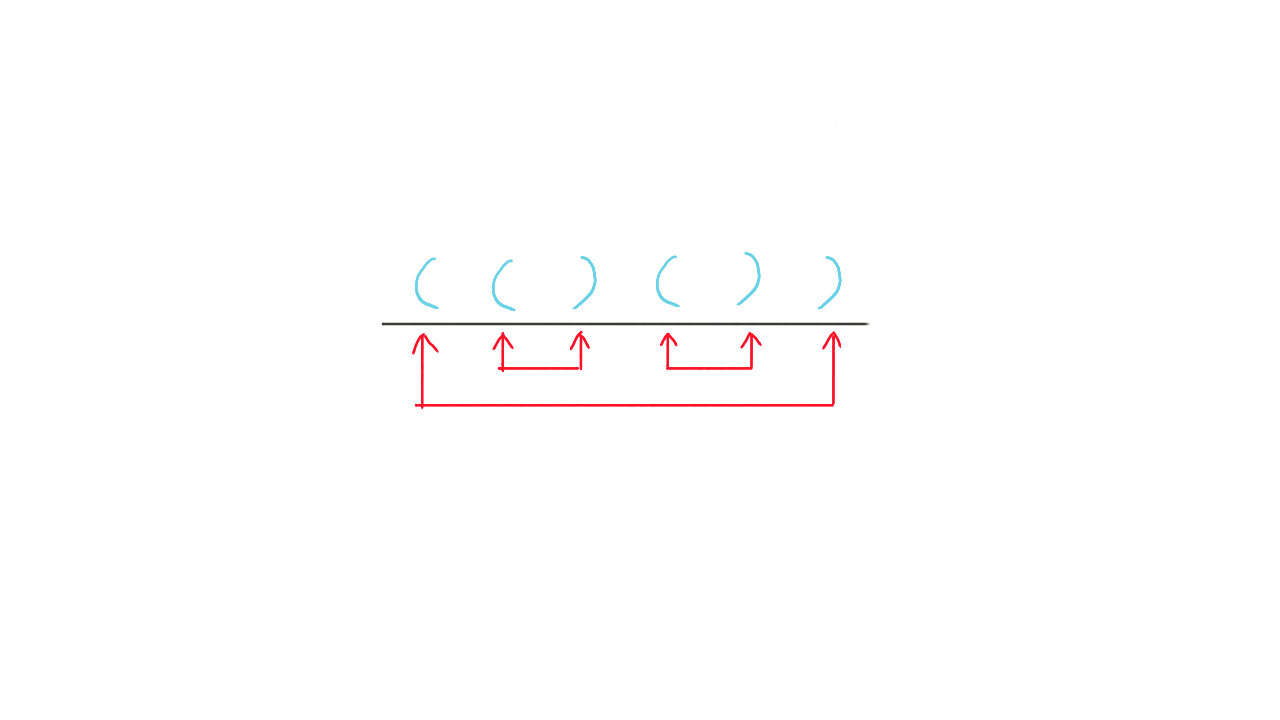
思路
左括号看成 +1,右括号看成 -1,那么就和上题的进出栈一样,共有 种序列。
push_back()函数
push_back()函数的用法
函数将一个新的元素加到vector的最后面,位置为当前最后一个元素的下一个元素
push_back() 在Vector最后添加一个元素(参数为要插入的值)
//在vec尾部添加10
vector<int> vec;
vec.push_back(10);
//在容器中添加10
int num = 10;
vector<int> vec;
vec.push_back(num);
或者再string中最后插入一个字符;
string str;
str.push_back('d');
类似的:
pop_back() //移除最后一个元素
clear() //清空所有元素
empty() //判断vector是否为空,如果返回true为空
erase() // 删除指定元素
accumulate函数
头文件
#include <numeric>
主要是用来累加容器里面的值,比如int、string之类,可以少写一个for循环
- 比如直接统计
vector<int> v里面所有元素的和:(第三个参数的0表示sum的初始值为0)
int sum = accumulate(v.begin(), v.end(), 0);
- 比如直接将
vector<string> v里面所有元素一个个累加到string str中:(第三个元素表示str的初始值为空字符串)
string str = accumulate(v.begin(), v.end(), "");
C的printf与scanf的用法
- 在C++中,是#include
.而在C中是#include<stdio.h>
- printf的用法是:printf(“格式控制字符串”,输出参数一,输出参数二);
格式控制字符串包含:格式控制说明,普通字符
格式控制说明主要是按指定的格式输出数据,包含以%开头的格式控制字符,不同类型的数据采用不同的格式控制字符(int型用%d,float和double用%f)
普通字符就是在输出数据的时候,按照原样输出的字符如:”fahr=%d,celsius=%d\n”中的fahr=,celsius=这些
- scanf的用法是:scanf(“格式控制字符串”,输入参数一,输入参数二);
格式控制字符串包含:格式控制说明,普通字符
格式控制字符串表示输入的格式,(int型用%d,float用%f,double型用%lf)
普通字符:和上面谈到的printf的用法是一样的
输入的参数是变量的地址,所以要在变量前面加&
——–格式控制说明———————————————————
%d 十进制有符号整数
%u 十进制无符号整数
%f 浮点数
%s 字符串
%c 单个字符
%p 指针的值
%e 指数形式的浮点数
%x, %X 无符号以十六进制表示的整数
%0 无符号以八进制表示的整数
%g 自动选择合适的表示法
——一些特殊规定字符———————————————————–
\n 换行
\f 清屏并换页
\r 回车
\t Tab符
\xhh 表示一个ASCII码用16进表示,
其中hh是1到2个16进制数
例子:
①
a=100,b=10;
printf("a=%d,b=%d\n",a,b);
//a=100,b=10
②
printf("enter x(x>=0):\n");
//enter x(x>=0):
③
x=12,y=16;
printf("y=f(%f)=%.2f\n",x,y);
//y=f(12.000000)=16.00
%f指定以小数形式输出浮点型数据,保留的是6位小数,而%.2f则指定输出的时候保留2位小数
④
x=10;
printf("%04d",x);
//0010
%04d 表示在输出一个小于4位的数值时, 将在前面补0使其总宽度为4位。
⑤
scanf("%lf",&x);//读取输入
调用scanf()函数输入数据,变量名x前面要加&,%lf中的l是long的首字母,scanf函数的输入参数必须和格式控制字符串中的格式控制说明相对应,
并且它们的类型,个数和位置要一一对`应。
scanf(“%d%d%lf”,&x,&y,&z)表示输入的x是int型的,y是int型的,z是double型的,这个就是一一对应



